TL;DR
- GraphRAG is a novel approach that leverages LLM-generated knowledge graphs to improve Retrieval-Augmented Generation (RAG) systems.
- By creating a structured knowledge graph, clustering it into semantic communities, and generating query-focused summaries, GraphRAG provides more comprehensive and diverse answers to complex, multi-hop questions.
- Evaluation on real-world datasets shows GraphRAG outperforming naive RAG in comprehensiveness and diversity, while offering efficient summarization techniques.
Retrieval-Augmented Generation (RAG) has emerged as a powerful technique for generating accurate and contextually relevant responses. However, traditional RAG methods often struggle with complex, multi-hop queries that require aggregating information from across the dataset. GraphRAG is a novel approach developed by Microsoft Research that leverages LLM-generated knowledge graphs to address these limitations and take RAG to the next level.
Prerequisites
Before diving into GraphRAG, it’s helpful to have a basic understanding of the following concepts:
- Retrieval-Augmented Generation (RAG): A technique that combines information retrieval and language generation to provide accurate and contextually relevant answers to user queries.
- Knowledge Graphs: Structured representations of information that capture entities, their attributes, and the relationships between them.
- Large Language Models (LLMs): Powerful AI models, such as ChatGPT, Claude, Mistral or Llama that can understand, generate, and reason with human language.
Understanding GraphRAG
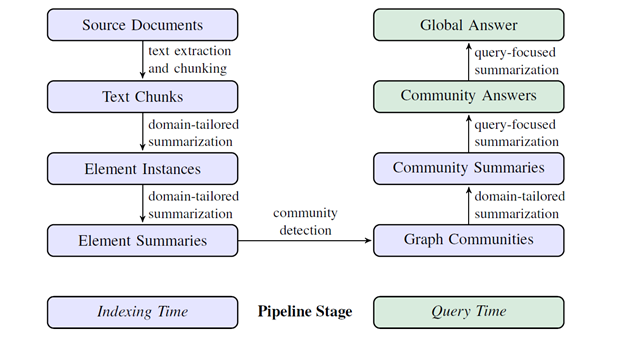
GraphRAG is a three-stage process that combines the power of knowledge graphs, semantic clustering, and query-focused summarization. Here’s how it works:
Knowledge Graph Creation:
GraphRAG uses LLMs to extract entities and their relationships from the source documents, creating a comprehensive knowledge graph. To create this knowledge graph, carefully crafted LLM prompts are used to extract entities, relationships, and other relevant information from the text chunks. These prompts are designed to identify key elements such as people, places, organizations, and the connections between them. By processing each chunk through the LLM, GraphRAG can construct a structured representation of the source documents, capturing the essential information needed for generating comprehensive and diverse answers
Semantic Clustering:
Once the knowledge graph is created, GraphRAG employs a technique called semantic clustering to organize the graph into closely-related groups of entities. Imagine you have a large collection of documents covering various topics. In the knowledge graph, entities that are frequently mentioned together or have strong connections will naturally form clusters. These clusters represent semantic communities – groups of entities that are closely related in meaning or context.
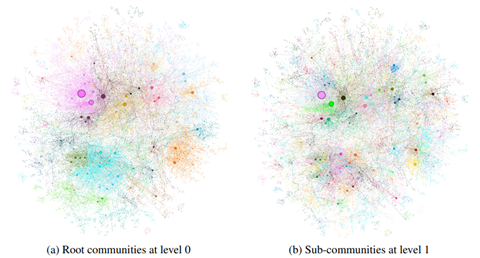
To identify these semantic communities, GraphRAG uses the Leiden algorithm, a powerful graph clustering method. The Leiden algorithm analyzes the structure of the knowledge graph, considering factors like the density of connections between entities and the overall modularity of the graph. By optimizing these factors, the algorithm can partition the graph into distinct semantic communities.
This semantic clustering step allows GraphRAG to efficiently navigate the knowledge graph and find relevant information for a given query. Instead of searching through the entire graph, GraphRAG can focus on the most relevant semantic communities, saving time and computational resources.
Query Processing:
When a user asks a question, GraphRAG uses the semantic communities to generate a comprehensive and diverse answer. The first step in query processing is to identify which semantic communities are most relevant to the user’s question. GraphRAG does this by comparing the entities and relationships mentioned in the question to those in each community.
Once the relevant communities are identified, GraphRAG generates a summary for each community. These summaries capture the key information contained within the community, providing a concise overview of the relevant entities, relationships, and context.
Finally, GraphRAG combines the community summaries to generate a final answer to the user’s question. This answer is designed to be both comprehensive, covering all the important aspects of the question, and diverse, incorporating information from multiple semantic communities to provide a well-rounded perspective.
Advantages of GraphRAG
So, what sets GraphRAG apart from traditional RAG methods? Two key advantages:
- Improved answer quality: GraphRAG consistently outperforms naive RAG in terms of comprehensiveness and diversity of answers. By leveraging the structure and semantic richness of knowledge graphs, GraphRAG can provide more complete and varied responses to user queries.
- Handling complex queries: GraphRAG excels at answering high-level, multi-hop questions that require aggregating information from multiple sources.
Imagine you’re a journalist trying to uncover the key insights from a massive collection of news articles. With GraphRAG, you can ask complex questions like “What are the most frequently discussed topics across different news categories?” and get a comprehensive, nuanced response that draws from the entire dataset.
Evaluation and Results
To put GraphRAG to the test, Microsoft researchers used two real-world datasets: podcast transcripts and news articles. They employed an activity-centered approach, generating global sensemaking questions that mimic how users might engage with the data in real-world scenarios.

To thoroughly evaluate GraphRAG’s performance, the researchers employed an activity-centered approach to generate global sensemaking questions. This approach involves creating questions that mimic the kinds of queries users might ask when engaging with the data in real-world scenarios. By grounding the evaluation in realistic user activities, the researchers could assess GraphRAG’s ability to provide comprehensive and diverse answers to complex, multi-hop questions that require aggregating information from across the dataset.
The evaluation compared six different conditions, each representing a different level of graph communities or text summarization:
- C0, C1, C2, and C3: These conditions correspond to different levels of the graph community hierarchy, with C0 being the root level and C3 being the most fine-grained.
- TS: A text summarization approach that applies the map-reduce summarization directly to the source texts, without using a graph index.
- SS: A naive ‘semantic search’ RAG approach that retrieves and concatenates relevant text chunks.
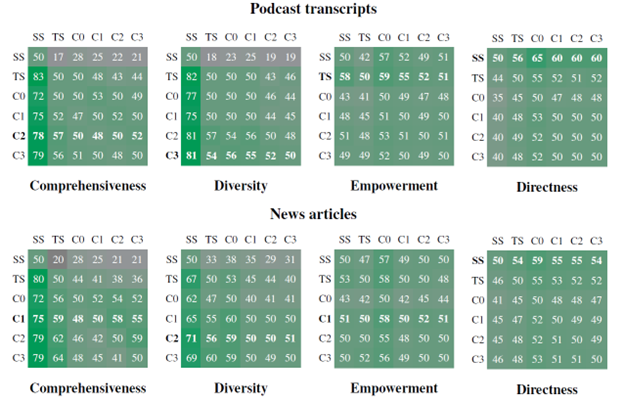
By comparing GraphRAG’s performance across these conditions, we can assess the impact of using different levels of graph communities and benchmark the approach against alternative methods like text summarization and naive RAG
- GraphRAG outperformed naive RAG in both comprehensiveness and diversity metrics, achieving win rates of 72-83% on podcast transcripts and 72-80% on news articles. In addition to comprehensiveness and diversity, the evaluation also considered two other key metrics: empowerment and directness.
- GraphRAG with intermediate and low-level community summaries showed favorable performance compared to global text summarization while requiring 26-33% fewer context tokens.
- Root-level community summaries offered a highly efficient method for iterative question-answering, using 97% fewer tokens than text summarization while still outperforming naive RAG.
Practical Implementation
To help you get started with GraphRAG, here’s a brief overview of the key steps involved in implementing this approach:
- Knowledge Graph Creation:
- Use an LLM, such as GPT-4, Claude or Llama3 to extract entities and their relationships from your source documents.
- Store the extracted information in a graph database, such as Neo4j or Amazon Neptune, to create a structured knowledge graph.
- Semantic Clustering:
- Apply a graph clustering algorithm, like the Leiden algorithm, to partition the knowledge graph into closely-related communities.
- Experiment with different hyperparameters to find the optimal clustering configuration for your specific use case.
- Query Processing:
- Generate query-focused summaries for each community in the knowledge graph using an LLM.
- When a user query is received, retrieve the relevant community summaries and use them to generate a comprehensive, diverse answer.
Conclusion
GraphRAG has significant potential for real-world applications in information retrieval, question-answering, and knowledge management. By enabling users to ask complex, multi-hop questions and receive comprehensive, diverse answers, GraphRAG can help journalists, researchers, and businesses unlock new insights from their data.
However, building a graph index for RAG systems does come with trade-offs. The computational cost and time required to generate the index must be weighed against the expected number of queries and the value of the insights generated.
Future research directions for GraphRAG include exploring hybrid RAG schemes that combine embedding-based retrieval with map-reduce summarization and developing exploratory “drill-down” mechanisms that allow users to interactively navigate the knowledge graph.
References: