TL;DR
Retrieval-Augmented Generation (RAG) systems combine information retrieval and language generation techniques to provide accurate and contextually relevant answers to user queries.
Ragas is a popular open-source evaluation framework that enables developers to assess and optimize the performance of their RAG pipelines.
By adopting a metrics-driven approach using Ragas, developers can make data-driven optimizations to enhance user experience and the quality of generated responses.
Ragas offers key metrics for assessing RAG performance:
Context Precision: evaluates the relevance and ranking of retrieved context chunks.
Context Recall: measures the retrieval of relevant context chunks from available documents.
Answer Relevancy: assesses the quality and conciseness of the retrieved context.
Faithfulness: measures the factual consistency of the generated answer with the context.
ragas: Evaluation for your RAG pipelines
Businesses and individuals are constantly seeking ways to access accurate, contextually relevant answers to their questions quickly and efficiently. However, the sheer volume of available information can make this a daunting task, leading to wasted time, frustration, and potentially costly mistakes. Retrieval-Augmented Generation (RAG) systems offer a promising solution to this challenge by combining the power of information retrieval and language generation techniques to provide users with concise, reliable answers to their queries. Evaluating RAG architectures is, however, challenging because there are several dimensions to consider: the ability of the retrieval system to identify relevant and focused context passages, the ability of the LLM to exploit such passages in a faithful way, or the quality of the generation itself.
Ragas aims to create an open standard, providing developers with the tools and techniques to leverage continual learning in their RAG applications. By incorporating Ragas into the development process, developers can:
Utilize LLM-assisted evaluation metrics: Ragas provides a set of objective, LLM-assisted evaluation metrics that allow developers to measure the performance of their RAG application accurately. These metrics take into account factors such as the relevance of the retrieved documents, the accuracy and contextual appropriateness of the generated answers, and the overall user experience.
Monitor quality in production with smaller, cheaper models: With Ragas, developers can deploy smaller, more cost-effective models in production to monitor the quality of their RAG application. These models can provide actionable insights, such as identifying instances of hallucinations in the generated answers, allowing developers to quickly address any issues and maintain a high level of reliability.
Synthetically generate a diverse test dataset: Ragas enables developers to create a comprehensive test dataset that represents a wide range of user queries and information needs. This synthetic dataset can be used to evaluate the performance of the RAG application, ensuring that it can handle a variety of real-world scenarios.
Iterate and improve based on insights: The insights gained from the evaluation metrics and production monitoring can be used to drive continuous improvement of the RAG application. Developers can use this feedback to fine-tune their models, optimize the retrieval and generation components, and enhance the overall user experience.
By leveraging the power of Ragas, developers can create RAG applications that not only provide accurate and contextually relevant answers but also continuously learn and improve over time. This metrics-driven approach ensures that the application remains reliable, up-to-date, and able to meet the evolving needs of its users.
In the following section, we’ll take a quick overview of how RAG systems work and the critical role that Ragas plays in ensuring their effectiveness and reliability.
The building blocks of a RAG System
Retrieval-Augmented Generation (RAG) systems are designed to provide accurate and contextually relevant answers to user queries by leveraging a combination of information retrieval and language generation techniques. At a high level, a RAG system works by first retrieving documents relevant to the user’s query, then augmenting the query with information from those documents, and finally generating an answer based on the augmented query. Let’s take a closer look at this process using the following visual:
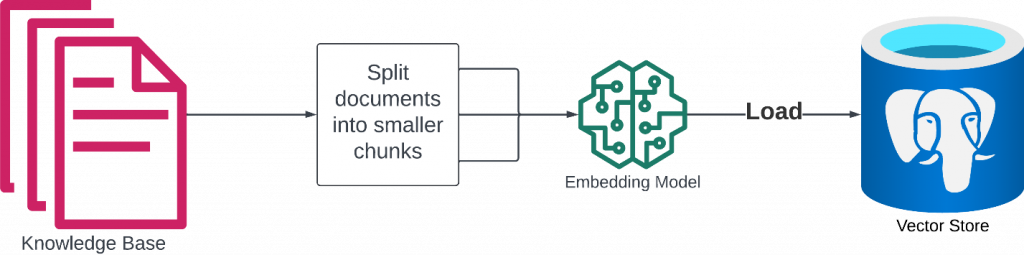
The RAG pipeline begins by splitting documents into smaller, more manageable chunks. These chunks are then processed through a vector embedding model that projects the semantic meaning of the document chunk into the embedding space. This form is ideal for detecting similarity to a user prompt during the retrieval step of a RAG pipeline.
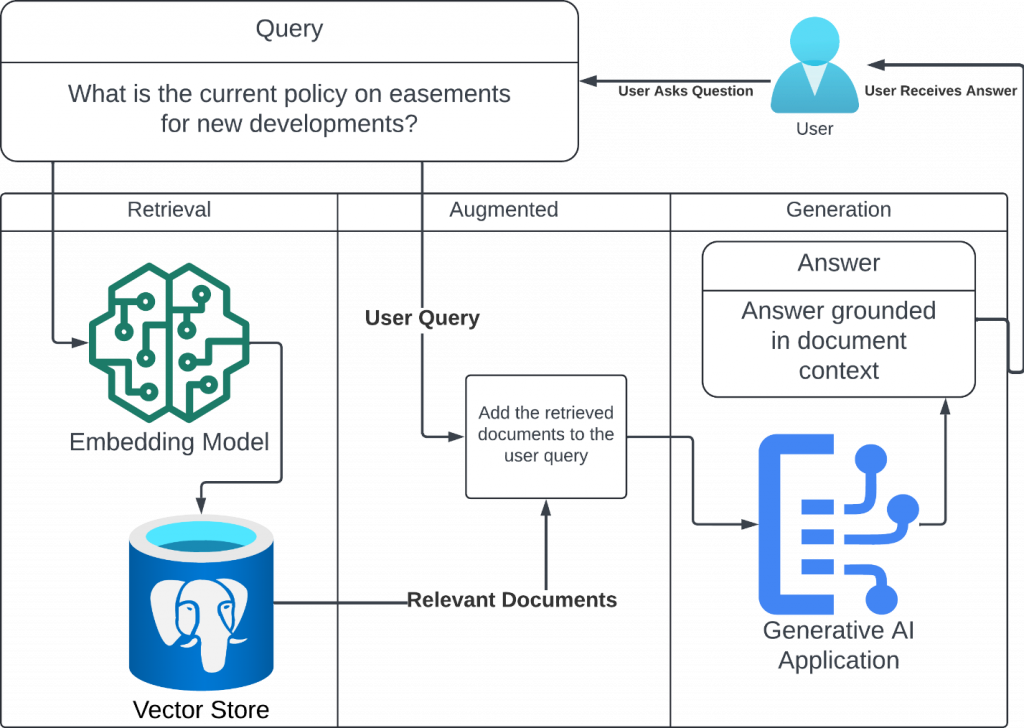
Once this vector store is built we can use it to pull relevant bits of information to a specific query or task and add that information into the generative model ( i.e ChatGPT, Claude, Mistral, etc). By adding the relevant documents into the context we provide a grounding (factual basis) to the outputs of the model.
By incorporating ragas into the development process of RAG systems, developers can gain valuable insights into the strengths and weaknesses of their models. The metrics provided by RAGAS help identify areas for improvement, such as fine-tuning the retrieval component to better identify relevant documents or optimizing the generation component to produce more accurate and contextually appropriate answers.
Moreover, by adopting a metrics-driven approach using RAGAS, developers can iterate more quickly and effectively on their RAG systems. The quantitative feedback provided by RAGAS allows for data-driven decision-making, enabling developers to make informed choices about model architecture, training data, and hyperparameters.
Assessing Retrieval Performance with RAGAS
To ensure that RAG systems are performing optimally, it’s essential to evaluate the effectiveness of both the retrieval and generation components. This is where the Retrieval Augmented Generation Assessment (RAGAS) framework comes into play. RAGAS focuses on evaluating two critical aspects of the RAG pipeline: retrieval and generation.
Effective retrieval ensures that the generated answer is grounded in the appropriate context and provides the necessary information to address the query. We do this by utilizing 4 primary components:
| Question | Answer | Context | Ground Truth |
|---|---|---|---|
| The query to the LLM | The answer generated by the LLM | The chunks returned by the Retriever | Facts expected to be present in the generated response. |
To assess the performance of the retrieval component, RAGAS offers several key metrics utilizing these components:
Retrieval Metrics
Context Precision:
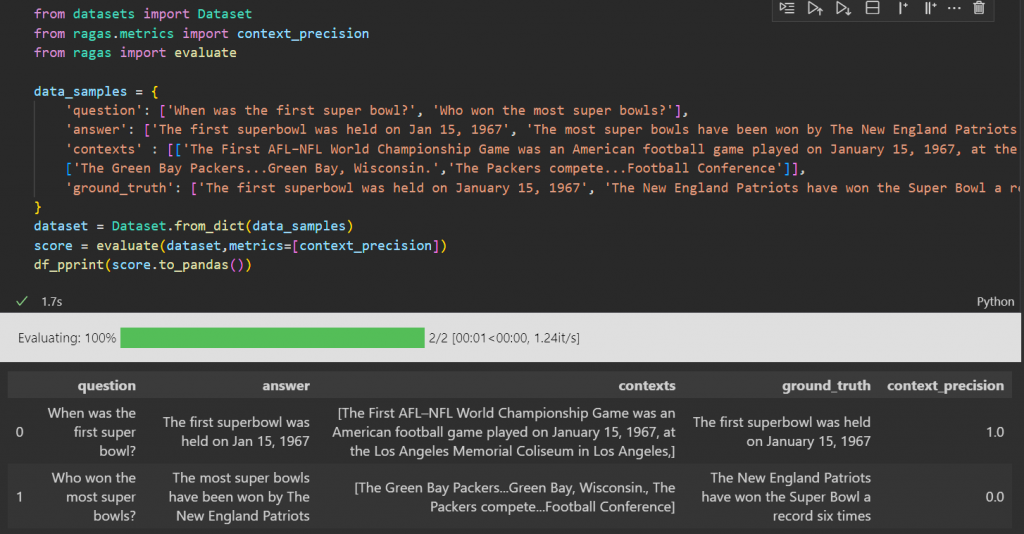
(Question <-> Context) This metric evaluates whether the retrieved context contains all the relevant information needed to answer the query. It measures the proportion of retrieved context chunks that are truly relevant to the query and the order they are ranked in.
Context Recall:
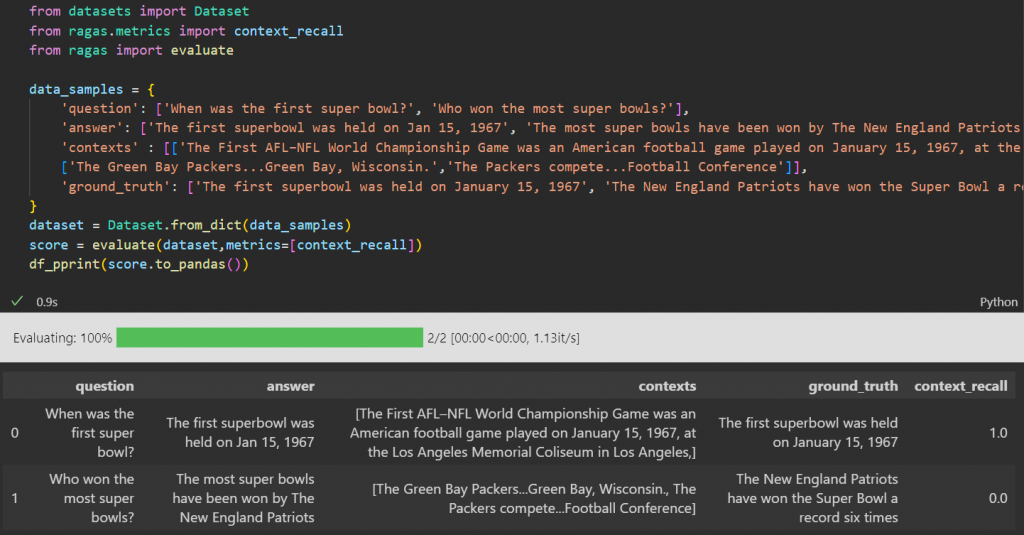
(Ground Truth <-> Context) Measures relation between ground truth and context. Context recall assesses the retrieval component’s ability to identify and retrieve all the relevant context chunks from the available documents. It measures the proportion of relevant context chunks that were successfully retrieved.
Generation Metrics
Answer Relevancy:
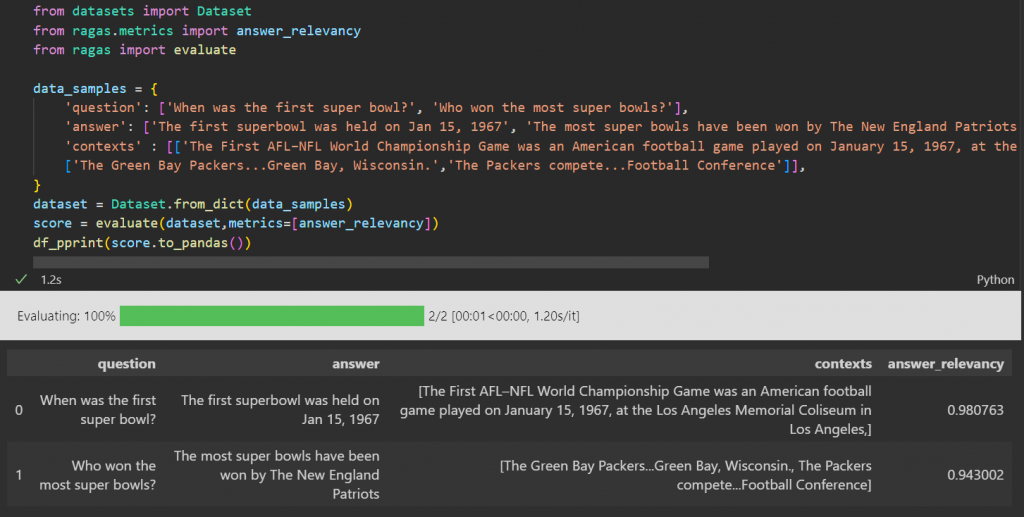
(Question <-> Answer) This metric focuses on the quality and conciseness of the retrieved context. It evaluates whether the retrieved context contains only the essential information needed to answer the query, penalizing the inclusion of irrelevant or redundant information.
Faithfulness:
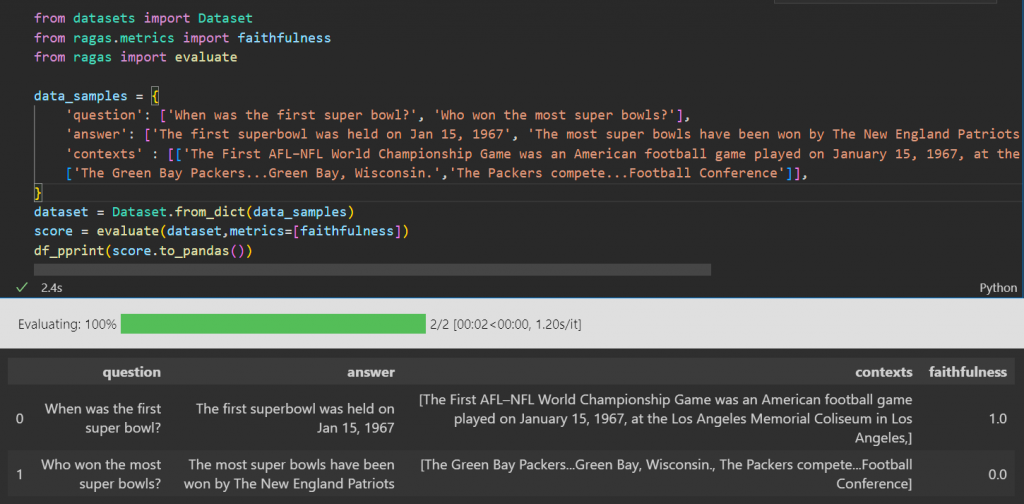
(Answer <-> Context) Measures the factual consistency of the generation. How much of the answer is grounded by the context? Is the generation hallucinating information it doesn’t have access to?
By employing these metrics, RAGAS provides a comprehensive evaluation of the retrieval component’s performance. It assesses the relevance of the retrieved context as well as its completeness and conciseness. This multi-faceted evaluation enables developers to identify strengths and weaknesses in their retrieval mechanism and make data-driven optimizations.
Effective retrieval is critical for the overall performance of RAG systems. By retrieving highly relevant and focused context chunks, the retrieval component sets the foundation for generating accurate and contextually appropriate answers. RAGAS empowers developers to assess and improve their retrieval mechanisms, ultimately enhancing the user experience and the quality of the generated responses.
In the next post in this series on RAG pipelines, we’ll connect our retriever model to a generator and utilize the rag pipeline to measure the performance of two different open source models against one another for a given dataset. Stay tuned!
References:
Comments
One response to “Assessing Retrieval Performance with RAGAS”
[…] A way to assess the query responses in LLM applications such as RAG is by utilizing RAG Assessment, or Ragas. Ragas involves using questions paired with ground truth statements that are then compared with answers to those same questions generated by LLMs. We have discussed Ragas in more detail here: Assessing Retrieval Performance with RAGAS – CFI Blog (cohesionforce.com). […]