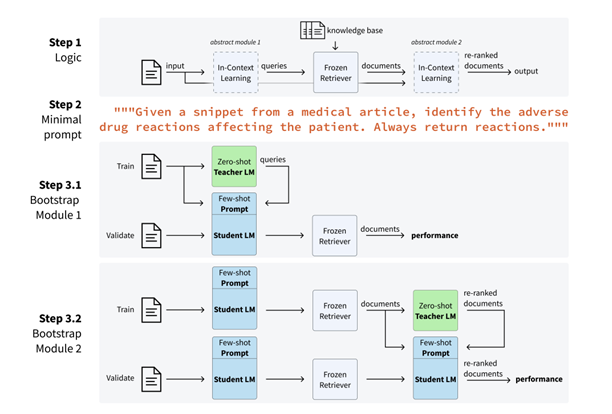
Advancements in language models have unlocked powerful new approaches for categorizing and organizing information. One such approach is the Infer-Retrieve-Rank (IReRa) framework. IReRa provides a structured method for taking raw input data, generating potential categories, refining those categories, and surfacing the most relevant results. In this post, we’ll break down the three key steps of IReRa and examine how they work together to enable more accurate and contextual categorization of data.
Prerequisites
Before diving in, familiarity with the following concepts will be helpful:
- Language Models: AI models trained to understand, generate, and classify human language. Key architectures include transformers (e.g., BERT, GPT).
- Knowledge Retrieval: The process of extracting relevant information from structured databases or knowledge graphs.
- Dense Vector Representations: Techniques for representing data (e.g., words, sentences, documents) as dense, fixed-length vectors that capture semantic meaning.
Hardware Requirements
The IReRa framework is designed to be versatile and can be deployed on both local machines and cloud-based platforms. One of the key advantages of RAG is its ability to significantly enhance the performance of smaller language models. This makes it an attractive option for users who may not have access to high-end hardware or extensive computational resources.
In our experiments, we have observed that quantized models with around 7 billion parameters, such as Mistral Instruct, can produce satisfactory results when combined with the IReRa framework. These models can comfortably run on consumer-grade hardware equipped with 8 GB of VRAM, making them accessible to a wide range of users.
For those seeking even better performance and more advanced capabilities, we recommend exploring the Yi series of models and their fine-tuned variants. These models have shown high performance for RAG and can deliver state-of-the-art results across various natural language processing tasks.
It’s worth noting that while more powerful hardware can certainly improve performance and speed up processing times, the IReRa framework’s efficiency allows it to leverage smaller models effectively. This makes it a compelling choice for applications where computational resources may be limited or where deployment on edge devices is required.
Infer: Generating Preliminary Categories
The first step in the IReRa process is Infer. A language model, often based on transformer architectures like Mistral or GPT, processes the raw input data and makes educated guesses about potential categories. The model relies on its pre-trained knowledge and understanding of the input’s context to generate these initial categories.
For example, given a product review for a blender, the model may identify categories like “kitchen appliances”, “blenders”, “product reviews”, etc. Techniques like few-shot learning, where the model is provided a small number of labeled examples, can help guide this inference process.
Retrieve: Aligning Inferences with Structured Knowledge
The next step is Retrieve. Using the initial categories from the Infer step, a retrieval system like SBERT (Sentence-BERT) searches through structured databases and knowledge graphs to find well-defined categories that best align with the preliminary guesses.
SBERT works by encoding the initial categories and the entries in the knowledge base into dense vector representations (also commonly referred to as embeddings) . It then uses cosine similarity to find the closest matches. This allows for efficient similarity search over large databases.
In our blender example, SBERT may match general categories like “kitchen appliances” and “blenders” to more specific product categories like “Countertop Blenders” or “Immersion Blenders”. This step helps map the initial inferences to a more refined, standardized taxonomy.
Rank: Prioritizing the Most Relevant Categories
The final step is Rank. A more advanced language model, like GPT-4, re-evaluates the retrieved categories and ranks them based on relevance and accuracy to the original input.
Various ranking algorithms can be used, such as pointwise, pairwise, or listwise approaches. Neural ranking models, which use deep learning to learn the ranking function directly from the data, are also popular.
For our blender review, the model would analyze the full text and determine the most applicable categories. It may rank “Countertop Blenders” as most relevant, followed by “Blenders”, with “Immersion Blenders” being less pertinent. This ensures the most salient categories are prioritized.
IReRa in Action: ML and Data Engineering Applications
The IReRa framework is highly relevant to machine learning and data engineering tasks. Some key applications include:
- Content Tagging: Automatically categorizing articles, blog posts, or documents based on their content.
- Product Categorization: Mapping product descriptions or reviews to standardized product categories in an e-commerce catalog.
- Efficient Data Annotation: Generating initial labels for data points to speed up manual annotation processes.
- Retrieval Augmented Generation : Selecting relevant documents for a search query to provide additional grounded context.
By improving the accuracy and contextual relevance of data categorization, IReRa can lead to better search and recommendation systems, more organized content repositories, and streamlined data preparation pipelines.
Implementing IReRa
To showcase how IReRa can be implemented, let’s walk through a simple example using Python and the Hugging Face Transformers library.
First, we’ll use the Mistral Instruct 7b model for the Infer step:
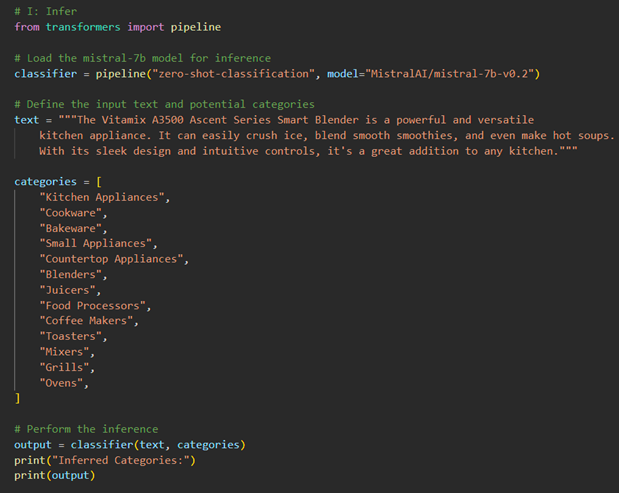
The output shows the inferred categories for the given input text about the Vitamix A3500 blender. The Mistral Instruct 7b model assigns scores to each category based on its relevance to the input text. The ‘labels’ list contains the categories, and the corresponding ‘scores’ list shows the confidence scores for each category. The highest scores are assigned to ‘Blenders’ and ‘Juicers’, indicating that the model has correctly identified the main categories related to the input text. We do see some items we would expect to be higher in the list like Countertop Appliances, Small Appliances, and Kitchen Appliances lower in the list than we would expect indicating the need to likely fine tune the model on our task for improved performance.
Example Output:

Next, we’ll use SBERT for the Retrieve step:

The output displays the top retrieved categories from the knowledge base using SBERT. These categories are most similar to the inferred categories from the previous step. The retrieved categories include ‘High-Performance Blenders’, ‘Countertop Blenders’, ‘Blender Accessories’, ‘Smoothie Makers’, and ‘Blender Recipes’. These categories provide more specific and relevant information related to the input text about the Vitamix blender.
Example Output:
Retrieved Categories: ['High-Performance Blenders', 'Countertop Blenders', 'Blender Accessories', 'Smoothie Makers', 'Blender Recipes']Then we’ll use a custom ranking function for the Rank step:
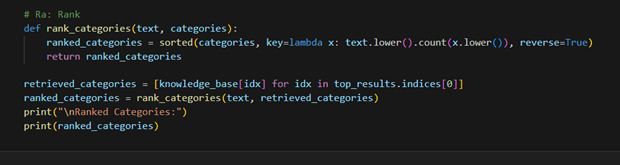
The output shows the ranked categories based on their relevance to the input text. The custom ranking function calculates the relevance by counting the occurrences of each category in the input text. The categories are then sorted in descending order based on their count. In this example, ‘Countertop Blenders’ is ranked first, followed by ‘High-Performance Blenders’, ‘Blender Accessories’, ‘Smoothie Makers’, and ‘Blender Recipes’. This ranking helps prioritize the most relevant categories for the given input text.
Example Output:
Ranked Categories: ['Countertop Blenders', 'High-Performance Blenders', 'Blender Accessories', 'Smoothie Makers', 'Blender Recipes']Conclusion and Next Steps
In this post, we explored the Infer-Retrieve-Rank framework for data categorization. We saw how IReRa combines language models, knowledge retrieval, and ranking techniques to enable more accurate and contextual categorization. We also discussed its applications in machine learning and data engineering and walked through a simple implementation using Python.
While powerful, IReRa does have some limitations. Dealing with ambiguous or multi-label categories can be challenging, and the quality of the results heavily depends on the language models and knowledge bases used. Extending IReRa to handle more complex scenarios is an active area of research.
In future posts, we’ll dive deeper into the individual components of IReRa, compare it to other categorization approaches, and explore advanced techniques for improving its performance. Stay tuned!
Comments
One response to “Understanding the Infer-Retrieve-Rank (IReRa) Framework”
[…] actionable insights. Through a series of flexible multistep flows (such as those laid out in our Infer-Retrieve-Rank blog post) the system helps ensure the right resources are leveraged for the […]